




By mid-2025, approximately 35% of new websites will have been created entirely or partially with the help of artificial intelligence, according to researchers at Stanford University.
Before the public launch of ChatGPT by OpenAI in November 2022, this figure was near zero. Over a few years, the share of AI-generated content has grown to more than a third of recent online publications.



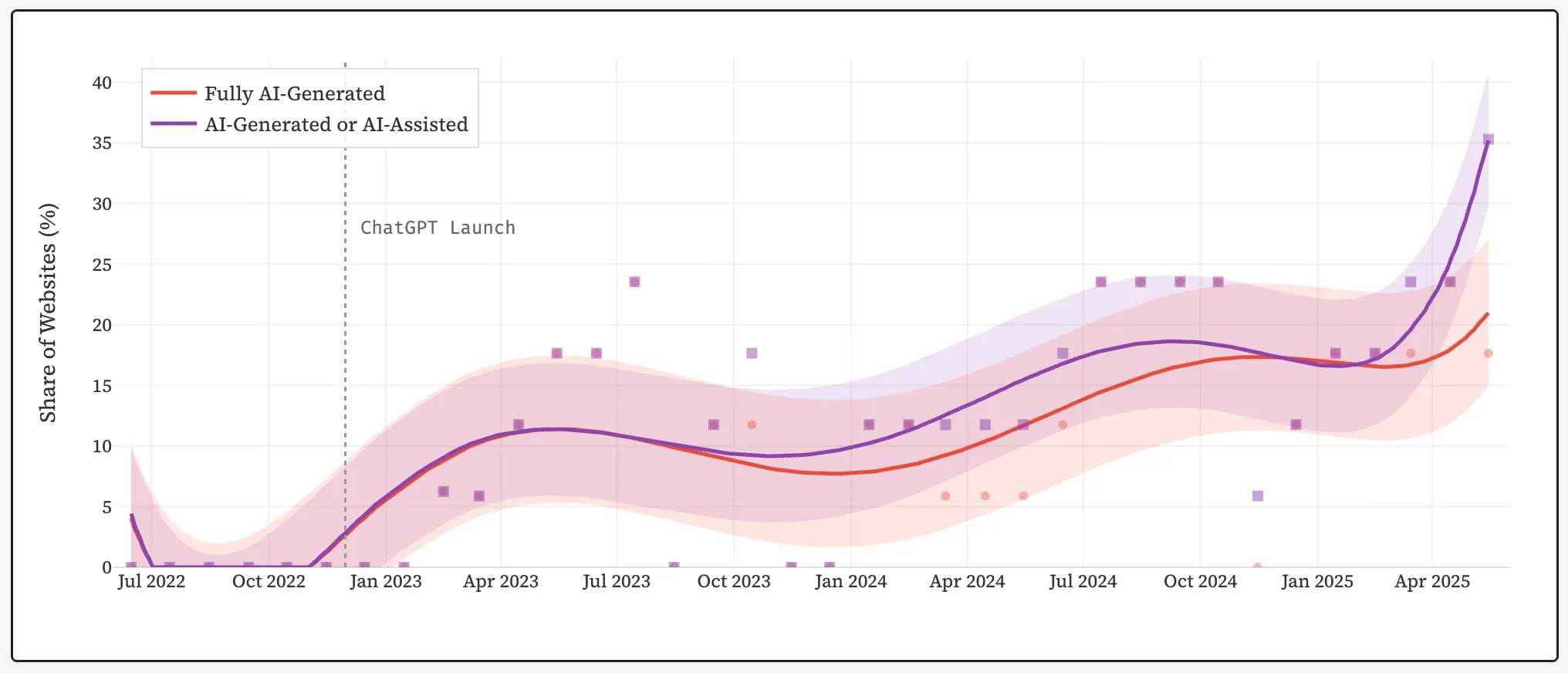
Scientists examined 33 months of archived website copies from the Wayback Machine using the Pangram v3 detector. The aim was to understand how the rise of AI-generated texts is reshaping the structure of the World Wide Web.
Key Changes
Researchers noted a decrease in semantic diversity. Pages generated by neural networks are 33% more similar to each other than texts written by humans. Different sites increasingly reiterate the same ideas in nearly identical phrases.
According to the authors, the issue is not merely mass AI-driven copywriting. The problem is deeper: the diversity of expressions and ideas is gradually narrowing. Large language models (LLM) inherently choose the most “average” responses, resulting in a reproduction of formulaic discourse.
The emotional tone of publications has also changed. AI content is found to be 107% more positive than human-written content. Stanford researchers linked this to the already documented tendency of LLMs towards flattery.
During training, developers optimize neural networks for pleasant, safe, and socially acceptable responses. As a result, a significant portion of new websites creates a “sterile and friendly” informational environment. This environment has fewer sharp judgments and conflicts, but also less lively human debate.
What Was Not Confirmed
Several popular concerns did not find statistical confirmation. Researchers did not find a significant correlation between the rise of AI content and a decline in factual accuracy, an increase in explicit errors, or the stylistic leveling of texts to a single template.

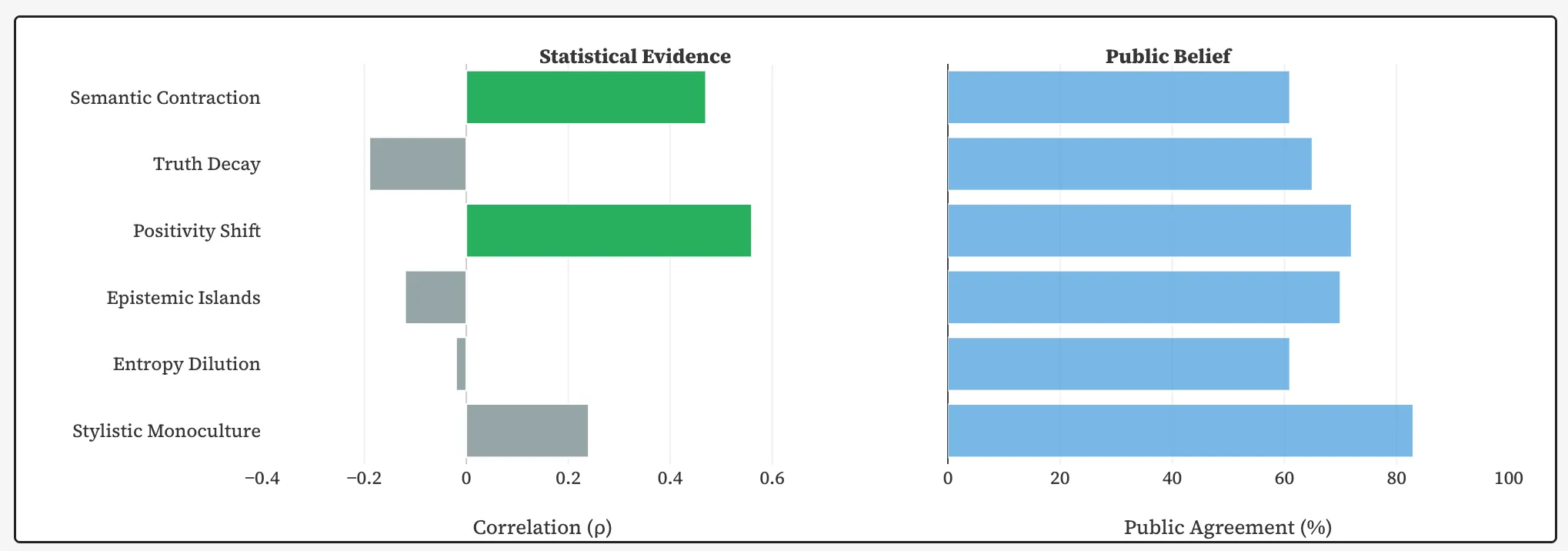
Scientists specifically pointed out an effect that has mostly been discussed theoretically until now—model collapse.
If new neural networks are trained on data with a lot of AI content, the system begins to process its own averaged responses. This reduces variability, degrades quality, and threatens that in the future, LLMs will learn not from humans but from the “synthetic echo” of their predecessors.
Experts, together with the Internet Archive, plan to turn the research into a system for continuous monitoring of the share of AI content on the internet.
In April, Stanford University highlighted the rapid pace of AI development. Researchers reported that neural networks are nearly matching humans in performing tasks on computers.