




Chinese AI startup DeepSeek has released a preview of its new line of language models. The flagship V4-Pro has surpassed Claude Opus 4.6 and GPT-5.4, becoming the best open system available.
🚀 DeepSeek-V4 Preview is officially live & open-sourced! Welcome to the era of cost-effective 1M context length.
🔹 DeepSeek-V4-Pro: 1.6T total / 49B active params. Performance rivaling the world’s top closed-source models.
🔹 DeepSeek-V4-Flash: 284B total / 13B active params.… pic.twitter.com/n1AgwMIymu— DeepSeek (@deepseek_ai) April 24, 2026
Architecture and Scale
The V4-Pro model comprises approximately 1.6 trillion parameters, but only 49 billion are used at each step. The second version, V4-Flash, has a total scale of 284 billion, with 13 billion activated.
Both models are built on a Mixture of Experts (MoE) architecture: only the subnetworks relevant to the task are activated for each token. This approach is more cost-effective than fully dense architectures while maintaining performance.
Pre-training was conducted on a corpus exceeding 32 trillion tokens. Developers then fine-tuned the models in stages, dedicating separate blocks for coding, mathematics, logic, and instruction following. The final version integrates these skills through distillation.
Long Context Made Affordable
A key distinction of V4 is the optimization for processing long sequences. While a 1 million token context window exists in other models, its use typically involves high costs and delays.
DeepSeek announced that the new version significantly reduced the resource demands of such operations. Compared to V3.2, V4-Pro requires about 27% of the computations and 10% of the memory KV cache when working with maximum context. For V4-Flash, the figures are approximately 10% and 7%, respectively.



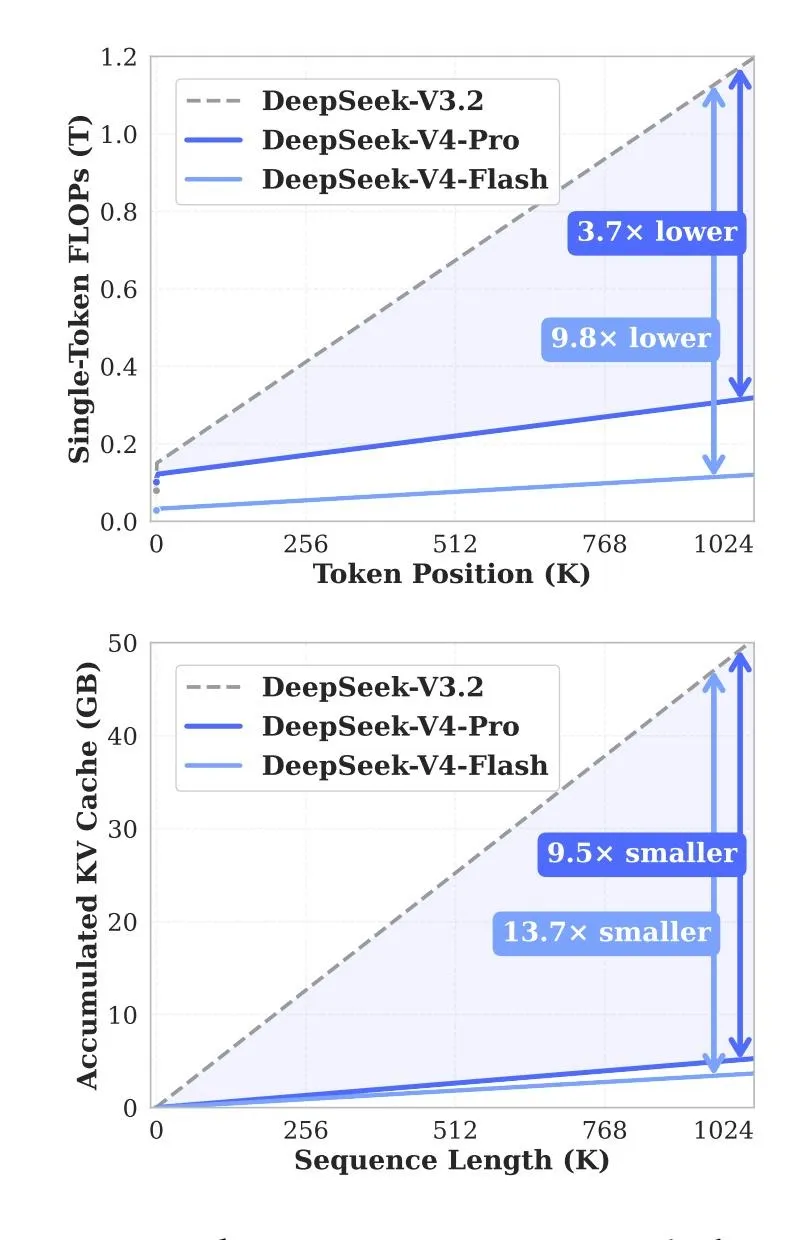
The team achieved this through a hybrid attention architecture: two mechanisms compress data and reduce load when handling long texts. Special hyperconnections were also used for stability, and the Muon optimizer accelerated training.
Reasoning Modes and Agent Capabilities
DeepSeek V4 supports three reasoning modes:
- Non-think — quick responses to simple questions without additional analysis.
- Think High — deep analysis for complex tasks and planning.
- Think Max — maximum mode: the model outlines each step and checks all options.
In agent tasks, the Max mode now retains the chain of intermediate steps within a single task. In the previous version, some of this context was lost during user interaction.
Testing Results
According to DeepSeek, the flagship version shows results comparable to leading systems in several areas:
- In programming tasks on Codeforces, the model achieved a rating of 3206 — 23rd place among active programmers worldwide, on par with GPT-5.4;
- In mathematics, it scored 95.2 on HMMT 2026 and 89.8 on IMOAnswerBench, surpassing most competitors;
- In SimpleQA Verified knowledge, it scored 57.9 (Opus 4.6 — 46.2, but Gemini 3.1 Pro — 75.6).
- In Reasoning, the models lag behind GPT-5.4 and Gemini 3.1 Pro by only three to six months;
- In DeepSeek’s internal test, including development, debugging, and refactoring tasks, the model achieved 67% — between Sonnet 4.5 (47%) and Opus 4.5 (70%);
- In agent scenarios and development tasks, V4-Pro-Max demonstrated 80.6% on SWE Verified and 67.9% on Terminal Bench.

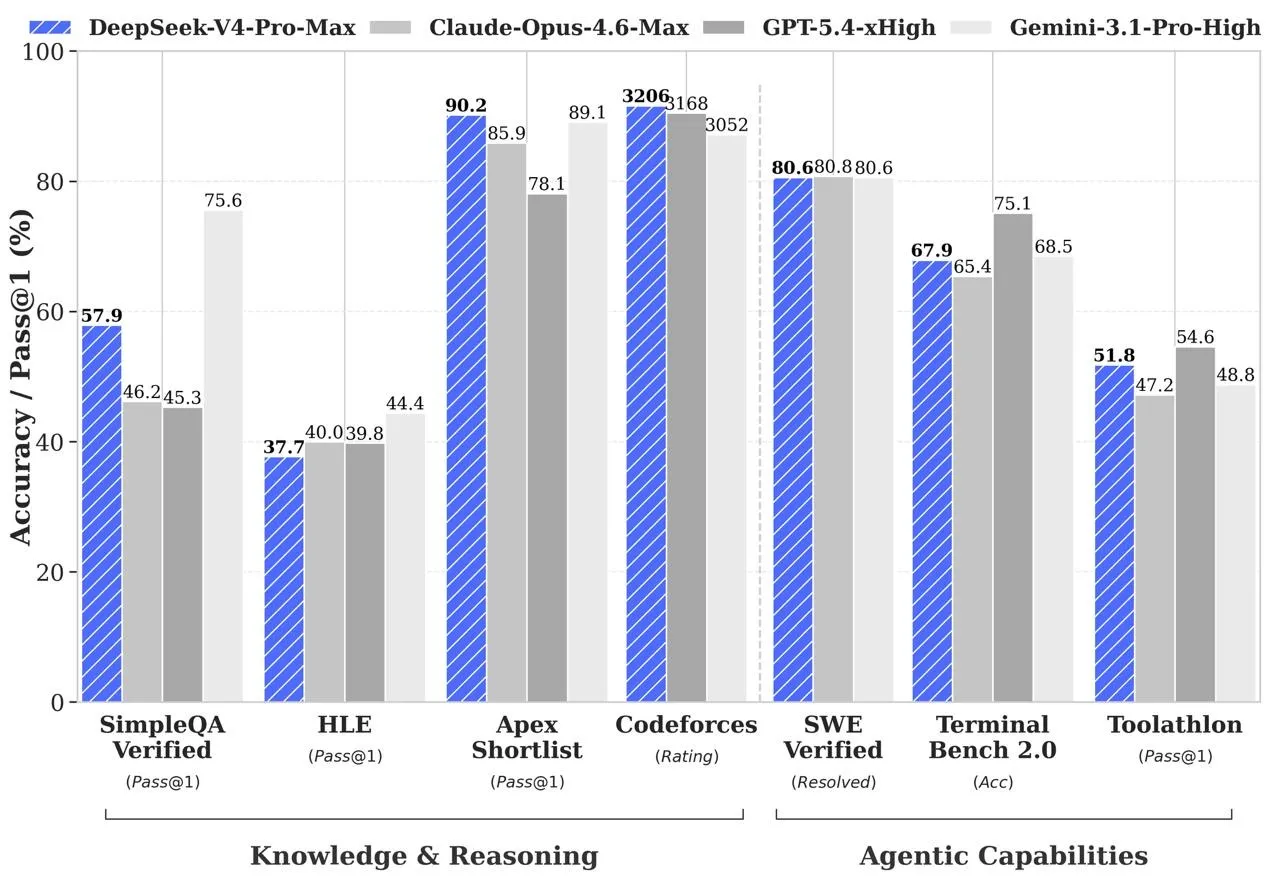
V4 was specifically trained on real-world scenarios: data analysis, reports, document editing, and internet searches with iterative tool use.
To assess the model’s suitability for real development, the startup conducted internal testing on tasks from its engineers. In a survey of 85 developers and researchers, 52% stated they are ready to use V4-Pro as their primary coding model, while another 39% indicated they are inclined to do so.
Back in April, OpenAI released GPT-5.5. The model is positioned as “a new level of intelligence for real work and agent management.”